私たちの日常生活に、音声アシスタントは急速に浸透しています。「Alexa、明日の天気は?」「OK Google、3分のタイマーをセットして」「Hey Siri、最寄りのカフェは?」——。まるでSF映画のように、機械と「会話」することが当たり前になりました。
彼らはまるで私たちの言葉を完全に理解しているかのように振る舞いますが、その裏側では一体何が起こっているのでしょうか?もちろん、それは「魔法」ではありません。そこには、人間の知性をコンピュータ上で再現しようとする、長年の研究と技術の粋が詰まっています。
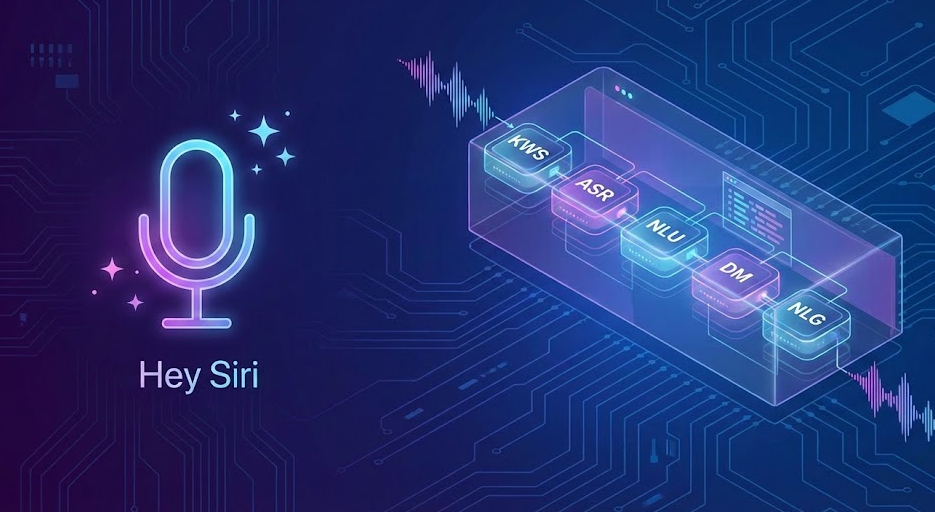
この記事では、あなたが「Hey Siri」と呼びかけてから、Siriが「はい、なんでしょう?」と応答するまでの、わずか数秒の間に起こっている驚異的なプロセスを、5つの主要な技術ステップに分解し紹介します。
音声技術の裏側に興味がある方、エンジニアを目指す学生、あるいは単に「どうなってるの?」と疑問に思ったことがあるすべての人の参考になれば幸いです。
音声アシスタントが応答するまでの全体像
私たちが音声アシスタントに話しかけるとき、その処理は大きく分けて以下の5つのステップで進みます。これらは一連の流れ作業(パイプライン)として、瞬時に連携して実行されています。
- キーワード・スポッティング (KWS): まず、アシスタントは「呼びかけ」に気づく必要があります。
- 自動音声認識 (ASR): 次に、あなたの「声」を「文字」に変換します。
- 自然言語理解 (NLU): そして、その「文字」が何を「意図」しているのかを理解します。
- 対話管理 (DM): 次に、理解した意図に基づいて「どう行動すべきか」を決定します。
- 自然言語生成 (NLG) & テキスト音声合成 (TTS): 最後に、「応答」を文章として組み立て、再び「声」にしてあなたに届けます。
それでは、各ステップを詳細に見ていきましょう。
1. キーワード・スポッティング (KWS): すべての始まり
キーワード・スポッティング (KWS): 「ウェイクワード」(例:「Alexa」「Hey Siri」)を検知する。
あなたのスマートフォンやスマートスピーカーは、常にあなたの会話の「すべて」を聞いているわけではありません。もしそうなら、それは重大なプライバシー侵害ですし、膨大なデータを常にクラウドに送り続けることになり、バッテリーや通信量も到底追いつきません。
ここで登場するのが、キーワード・スポッティング (KWS)、通称「ウェイクワード検出」です。
🔒 プライバシーと効率の番人
KWSは、デバイス上で(オフラインで)動作する、非常に軽量で電力効率の高い「耳」だと想像してください。その唯一の仕事は、周囲の音の中から、あらかじめ定められた特定の単語(「Alexa」「OK Google」など)だけを聞き取ることです。
このKWSエンジンは、デバイスのマイクが拾う音声を常時監視していますが、ウェイクワード以外の音声データは、デバイス内の小さなメモリ(リングバッファ)に一時的に保存され、ウェイクワードが検出されなければ即座に破棄されます。
KWSがウェイクワードを検知した瞬間、初めて「録音開始」の合図が出ます。通常、ウェイクワードが発話される直前の数秒間の音声データと、その後のユーザーの指示(例:「明日の天気は?」)がセットで録音され、次のステップであるASRエンジン(多くの場合、クラウド上にある)に送信されます。
🧠 軽量な頭脳
KWSはなぜデバイス上で軽量に動作できるのでしょうか?
それは、「すべての言葉」を理解する必要がなく、「特定の単語」だけを認識できれば良いからです。このため、使われるAIモデルも非常に小さく最適化されています。
具体的には、マイクから入ってきた音声波形は、まず「音響特徴量」(MFCCなど、音声の特性を数値化したもの)というデータに変換されます。この特徴量を、小さなニューラルネットワーク(CNNや軽量なRNNなど)に入力し、「これはウェイクワードか、そうでないか」という単純な確率計算を常時行っています。
⚖️ 誤認識との戦い
KWSの設計は、「聞き逃し」と「聞き間違い」のトレードオフとの戦いです。
- 聞き逃し (False Negative): あなたが「Hey Siri」と呼んだのに、Siriが反応しない状態です。これはユーザーにとって非常にストレスです。
- 聞き間違い (False Positive): テレビの音や家族の会話に反応して、アシスタントが突然起動してしまう状態です。これはプライバシーの観点からも望ましくありません。
メーカー各社は、このバランスを最適化するために膨大なデータ(様々なアクセント、騒音環境、距離で録音されたウェイクワード)を使ってモデルを学習させています。
KWSは、音声アシスタントが「常に聞いている」という恐怖感を和らげ、必要な時だけ「耳を傾ける」というスマートな体験を実現するための、最初の、そして最も重要な関門なのです。
2. 自動音声認識 (ASR): 「声」を「文字」に変換する
自動音声認識 (ASR): 人間の発話をテキストデータに変換する。
KWSによって起動が確認されると、いよいよ本格的な「音声認識」が始まります。ASR(Automatic Speech Recognition)の役割は、KWSが録音したあなたの「音声データ(波形)」を、コンピュータが処理できる「テキストデータ(文字列)」に変換することです。
これは、私たちが「聞く」という行為を、コンピュータがいかにして実現しているか、という問題であり、音声アシスタント技術の中核の一つです。
☁️ クラウドの力、あるいはデバイスの力
ASRの処理は非常に計算コストが高いため、多くの場合、録音された音声データはインターネットを経由して、Amazon、Google、Appleなどが運用する強力なサーバー(クラウド)に送信されます。クラウド上では、超高性能なAIモデルが待機しており、瞬時に音声をテキストに変換します。
しかし、最近ではスマートフォンのAIチップ(AppleのNeural Engineなど)の性能が向上したため、「オンデバイスASR」も増えています。これは、通信環境が悪い場所でも使え、プライバシー面でもより安全(音声データがデバイスの外に出ない)という利点があります。
🧬 ASRの仕組み:音と文脈の解読
ASRが音声をテキストに変換するプロセスは、大きく分けて「音響モデル」と「言語モデル」という2つのAIモデルの連携によって成り立っています。(※近年はこれらを統合したEnd-to-Endモデルが主流になりつつありますが、概念を理解するために分けて説明します)
- 音響モデル (Acoustic Model):
- 役割: 音声データ(波形)を、「音素」(”k”や”a”のような、言語を構成する音の最小単位)の列に変換します。
- 仕組み: 音声データを非常に短い時間(数十ミリ秒)ごとに区切り、その音響的特徴を分析します。ディープニューラルネットワーク(DNN)が、その特徴がどの「音素」に最も近いかを確率的に予測します。
- 例: 「こんにちは」という音声は、[k][o][N][n][i][ch][i][w][a] のような音素の並びとして認識されます。
- 言語モデル (Language Model):
- 役割: 音響モデルが生成した「音素の並び」から、最も「ありそうな」(=文法的に正しく、意味が通る)単語の並び(=文章)を推測します。
- 仕組み: 大量のテキストデータ(ウェブサイト、書籍、ニュース記事など)をAIに学習させ、「この単語の次には、この単語が来やすい」という「言葉のつながり(確率)」を覚えさせます。
- 例: 音響モデルが「きょーわいーてんき」と認識したとします。言語モデルは、
- 「強はいい天気」
- 「今日はいい天気」
- 「今日は胃天気」 といった複数の候補の中から、「今日はいい天気」という組み合わせが最も出現確率が高い(=最も自然な日本語である)と判断し、これを選択します。
🌪️ ASRが直面する「現実」の壁
ASRは完璧ではありません。私たちが日常でいかに「雑」に話しているかを思い知らされます。
- 騒音: カフェの雑談、電車の走行音、テレビの音など(カクテルパーティー効果)。
- 話し方: 早口、言い淀み(「えーっと」「あのー」)、方言、アクセント。
- 同音異義語: 「はし」が「橋」なのか「箸」なのか「端」なのか。
- 固有名詞: 「鬼滅の刃」や「呪術廻戦」のような新しい言葉や、人名、地名。
現代のASR、特にTransformerベースの「Conformer」や「Wav2Vec」といった最先端のモデルは、これらの課題を克服するために、膨大なノイズ入りデータや、文脈全体を考慮する仕組みを取り入れ、日々進化を続けています。
3. 自然言語理解 (NLU): 「文字」の「意図」を汲み取る
自然言語理解 (NLU): テキストの意味とユーザーの意図を理解する。
ASRによって、あなたの声は「今日はいい天気だね」という「テキスト(文字列)」に変換されました。しかし、コンピュータにとって、これはまだ単なる「文字の羅列」に過ぎません。
ここで、自然言語理解 (NLU, Natural Language Understanding) の出番です。NLUの役割は、そのテキストが「何を意味し」「ユーザーは何をしたいのか」という「意図」を抽出することです。
「何を言っているか」から「何をしたいのか」へ。これがNLUの核心です。
🎯 意図とスロットの抽出
NLUは、入力されたテキストを分析し、主に2種類の情報を抽出します。
- 意図 (Intent) の分類:
- ユーザーの発話の「目的」や「カテゴリ」を特定します。
- 例:「アラームを7時にセットして」 →
Intent: set_alarm - 例:「今日の東京の天気は?」 →
Intent: get_weather - 例:「ビートルズの曲をかけて」 →
Intent: play_music - 例:「1+1は?」 →
Intent: calculate
- スロット (Slot) の抽出 (固有表現抽出, NER):
- その意図を実行するために必要な「具体的な情報(パラメータ)」をテキスト中から抜き出します。
- 例:「アラームを7時にセットして」
Intent: set_alarmSlot: { time: "7時" }
- 例:「今日の東京の天気は?」
Intent: get_weatherSlot: { date: "今日", location: "東京" }
- 例:「ビートルズのHey Judeをかけて」
Intent: play_musicSlot: { artist: "ビートルズ", song_title: "Hey Jude" }
NLUは、ASRが生成したテキストを、{ "Intent": "get_weather", "Slot": { "date": "今日", "location": "東京" } } のような、コンピュータが処理できる「構造化データ」に変換するプロセスなのです。
🧠 文脈を読み解くAI
この意図とスロットの抽出は、どのように行われているのでしょうか?
かつては「天気」「気温」という単語が含まれていれば get_weather と判断するような、単純なルールベースが主流でした。しかし、これでは「天気を操作したい」のような比喩表現や、「明日の服装、どうしよう?」といった間接的な表現に対応できません。
現代のNLUは、ASRと同様に、ディープラーニング、特にTransformerベースのモデル(BERTやその後継モデル)によって支えられています。これらのモデルは、大量の文章を学習することで、「単語そのもの」だけでなく、「文脈の中での単語の使われ方」を理解します。
- 「Appleの株価」 → この”Apple”は「会社」を意味する。
- 「Appleが食べたい」 → この”Apple”は「果物」を意味する。
NLUは、このように文脈に応じて単語の意味を解釈し、発話全体の「真の意図」を高い精度で汲み取ろうとします。
❓ 曖昧性という最大の敵
NLUの最大の課題は「曖昧性」です。 「電気つけて」→ どこの電気?リビング?寝室? 「Apple Musicかけて」→ 「Apple」というアーティストの「Music」という曲? それとも「Apple Music」というサービス?
ASRの認識ミス(例:「東京」が「東響」になる)がNLUに伝わると、意図の解釈はさらに困難になります。NLUは、ASRから渡された(時には間違っているかもしれない)テキストを元に、ユーザーが「本当に言いたかったこと」を推測するという、非常に高度なタスクを担っているのです。
4. 対話管理 (DM): 会話の流れを操る「司令塔」
対話管理 (DM): 会話の状態を追跡し、システムが次に取るべき行動を決定する。
NLUによって、アシスタントは「ユーザーが天気(場所:東京、日時:今日)を知りたがっている」こと(Intent: get_weather, Slot: ...)を理解しました。
さて、次に何をすべきでしょうか?ここで登場するのが、対話管理 (DM, Dialogue Manager) です。DMは、音声アシスタントの「司令塔」や「脳の中枢」に例えられます。
DMの役割は、NLUから受け取った「理解」に基づき、システム全体(天気API、音楽プレーヤー、アラーム機能など)に対して「次に取るべき行動」を決定することです。
📝 会話の状態を「記憶」する
DMの最も重要な機能の一つが、対話状態の追跡 (Dialogue State Tracking, DST) です。これは、会話の「今、ここ」に至るまでの文脈や情報を「記憶」し、管理する機能です。
単発の質問(例:「今日の天気は?」→「晴れです」)であればDMは単純ですが、「対話」はそうはいきません。
ユーザー: 「東京の天気を教えて」
DM (DST):state = { location: "東京" }を記憶。
DM (Action):get_weather(location="東京")を実行 → 天気APIから「晴れ、25度」を取得。
アシスタント: 「東京は晴れ、最高気温は25度です」
ユーザー: 「大阪は?」
ASR: 「大阪は?」
NLU:Intent: get_weather(暗黙の意図),Slot: { location: "大阪" }
DM (DST):stateのlocationを “東京” から “大阪” に更新。
DM (Action):get_weather(location="大阪")を実行。
このように、DMが「直前の会話は天気についてだった」と記憶しているからこそ、「大阪は?」という省略された発話でも、ユーザーが「大阪の天気」を知りたいのだと文脈的に判断できるのです。
🚸 次の行動を「決定」する
DMは、現在の「状態」とNLUの「理解」に基づき、次の行動(Action)を決定します。
- 情報が十分な場合 → API呼び出し / 機能実行
- NLUが
Intent: set_alarm,Slot: { time: "7時" }を返した場合。 - DMは
action: device.set_alarm(time="7時")という内部コマンドを実行します。
- NLUが
- 情報が不足している場合 → ユーザーへの質問
- ユーザー: 「アラームをセットして」
- NLU:
Intent: set_alarm,Slot: {}(スロットが空) - DM: アラーム設定には「時間」が必須だが、スロットが空であることを検知。
- DM (Action):
action: request_missing_info(slot="time") - (これが次のNLGステップに渡され、「何時にセットしますか?」という応答が生成されます)
- 情報が曖昧な場合 → 確認
- ユーザー: 「でんきをつけて」
- NLU:
Intent: turn_on_light - DM (DST):
stateには「リビングの電気」「寝室の電気」が登録されている。 - DM: どちらか特定できない。
- DM (Action):
action: clarify(target="light") - (NLGへ → 「どちらの電気ですか?リビングですか、寝室ですか?」)
このように、DMは単なる応答マシンではなく、対話を能動的に管理し、ゴール(ユーザーの意図の達成)に向けて会話をナビゲートする、非常に知的なシステムなのです。その実現方法も、単純なルールベースから、強化学習を用いて「最適な次の行動」を学習する高度なAIまで多岐にわたります。
5. 自然言語生成 (NLG) & テキスト音声合成 (TTS): 「応答」を創り出し、「声」にする
自然言語生成 (NLG) & テキスト音声合成 (TTS): 応答テキストを生成し、それを自然な音声波形に変換して発話する。
DMが「get_weather(location="東京") を実行し、結果として { weather: "晴れ", temp_max: 25 } を得た」とします。 DMは次の行動として action: inform_weather(location="東京", weather="晴れ", temp_max=25) を決定しました。
しかし、この {...} というデータ構造を、そのままユーザーに返すわけにはいきません。最後のステップは、この「コンピュータの理解」を、再び「人間の言葉」と「音声」に戻すことです。
このステップは、自然言語生成 (NLG, Natural Language Generation) と テキスト音声合成 (TTS, Text-to-Speech) という2つのプロセスで構成されます。
✍️ 自然言語生成 (NLG): 「何を」言うか
NLGの役割は、DMから渡された「行動」と「データ」を元に、自然な「応答文(テキスト)」を生成することです。
- 入力:
action: inform_weather(location="東京", weather="晴れ", temp_max=25) - 出力(例): 「東京の今日の天気は晴れで、最高気温は25度です。」
NLGの実現方法には、いくつかのレベルがあります。
- テンプレートベース:
- 最も単純な方法。「[場所]の今日の天気は[天気]で、最高気温は[気温]度です。」という「穴埋め式の型(テンプレート)」をあらかじめ用意しておき、DMからのデータを流し込むだけです。
- 高速で確実ですが、応答が常にワンパターンで、ロボット的になりがちです。
- ニューラルNLG (AIによる生成):
- 近年、GPTに代表される大規模言語モデル(LLM)の技術がNLGに応用されています。
- AIがデータと文脈を解釈し、「ゼロから」応答文を生成します。
- これにより、同じ情報でも多様な表現が可能になります。
- 「東京は今日、25度まで上がる良い天気になりそうですよ。」
- 「はい、東京の天気ですね。今日は晴れです。」
- (雨の場合)「あいにくですが、東京は今日一日、雨が続くようです。」
- このように、より人間らしく、状況(例えば、良い天気か悪い天気か)に応じたニュアンスを含めた応答が可能になります。
🗣️ テキスト音声合成 (TTS): 「どう」言うか
NLGによって「東京は晴れです」というテキストが生成されました。最後の仕上げは、このテキストを「音声」に変換する テキスト音声合成 (TTS) です。
かつてのTTS(カーナビの音声などを想像してください)は、録音された人間の声の「音素」や「音節」を切り貼りして繋ぎ合わせる方式(波形接続型)が主流でした。これは明瞭ではあるものの、どこか不自然で、継ぎ目が目立つ「ロボット声」になりがちでした。
しかし、現代の音声アシスタントが搭載するTTSは、ディープラーニングによって劇的に進化しています。
- ニューラルTTS (WaveNet, Tacotronなど):
- これらのAIモデルは、大量の「テキスト」と「それに対応する人間の発話音声」を学習します。
- AIは「このテキストは、人間ならどのような抑揚、リズム、間で発話するか」を学び、音声波形そのものをゼロから生成します。
- その結果は驚くほど自然で、単語と単語のつながりが滑らかであり、文脈に応じた適切な「抑揚」や「感情」(喜び、謝罪、驚き)さえも表現できるようになってきています。
このNLGとTTSが組み合わさることで、アシスタントは単に情報を読み上げるのではなく、「人間らしい声」で「自然な言葉」を「発話」することができるのです。
まとめ:技術の結晶としての音声アシスタント
「Hey Siri」という呼びかけから、アシスタントが応答するまでの数秒間。
- KWS があなたの声を待ち受け、
- ASR があなたの「声」を「文字」に変え、
- NLU がその「文字」から「意図」を読み取り、
- DM が「意図」と「文脈」から「次の一手」を考え、
- NLG & TTS がその「答え」を「人間らしい言葉と声」で紡ぎ出す。
私たちが日常的に触れている音声アシスタントは、これら5つの(実際にはさらに細分化された)最先端技術が、高速かつシームレスに連携することで初めて成立する「技術の結晶」です。
ディープラーニングの進化、特にTransformerモデルや大規模言語モデル(LLM)の登場により、これらの技術(特にASR, NLU, NLG)の精度は飛躍的に向上しました。
しかし、課題はまだ山積みです。複数の人が同時に話す環境での聞き分け、カメラ映像なども使ったマルチモーダルな理解(「あれ、取って」で通じるアシスタント)、そして何より、ユーザーの「心」を理解するような、真の対話パートナーへの道は、まだ始まったばかりです。
次にあなたが音声アシスタントに話しかけるとき、その返事の裏側で懸命に働く、この複雑で精巧な「知性」の連鎖に、少しだけ思いを馳せてみてはいかがでしょうか。

コメント